LangChain~ Retrieval Augmentation Generation~~
Build RAG from Scratch~
There are several steps to build a RAG system from scratch.
- Loading documents.
- Chunk the documents into splits and embed the splits.
- Store the embedded splits into a vector store, and make it a retriever for finding the top ‘k’ relevant splits by calculating the similarity between the question and the document splits.
- Combine the retrieved document splits and the question into the prompt.
- Load the LLM.
- Create Chain with prompt and llm, then use
chain.invoketo generate the answer.
Section 1: Query Translation
Modify the questions from the users to make them more suitable to retrieval from the indexes(documents).
General approaches:
- Step-back question (Step-back prompting)
- Question Re-written (RAG-Fusion, Multi-Query)
- Sub-Question (‘Least to Most’ from Google)
Multi-Query
Use an LLM to transform a question into multiple perspectives.
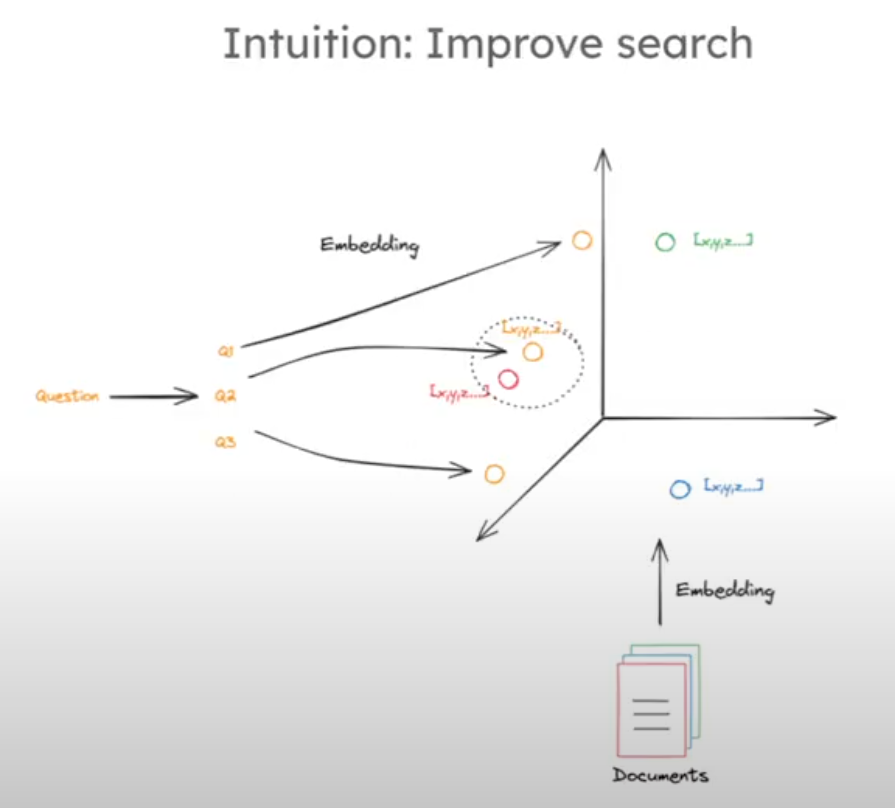
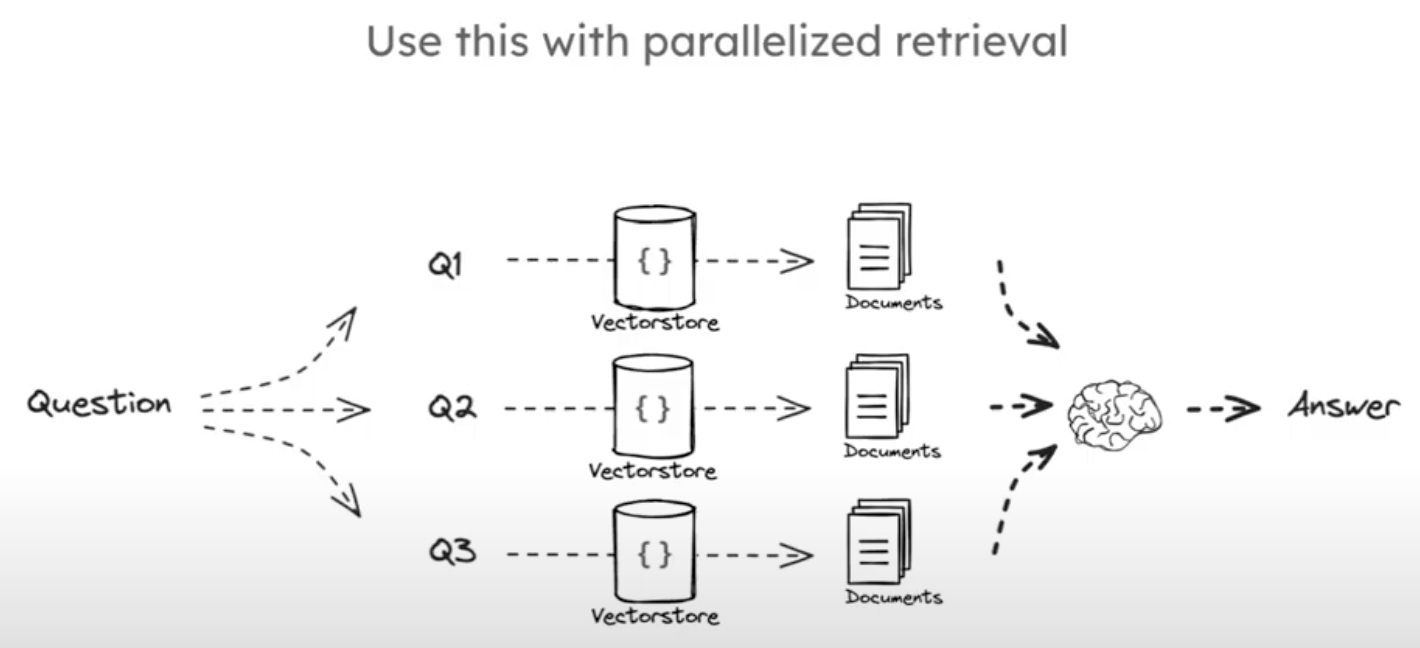
Section 2: Routing
Route the questions to the right data source (relation DB, graph DB, vector store).
Section 3: Query Construction
Taking natural language and converting it into the DSL (Domain Specific Language) necessary for whatever data source you want to work with.
Construction Examples:
- text to SQL (Relational DBs)
- text to Cypher (GraphDBs)
- self-query retriever (VectorDBs)
Section 4: Indexing (VectorStores Implementation)
“Indexing makes the documents easier to be retrieved.”
Indexing Process:
- The documents are split into small chunks, embedded and stored in an ‘Index’.
- Given a question which is embedded.
- The ‘Index’ performs a similarity search, and returns the splits relevant to the question.
OpenAI Tokenizer Library: tiktoken Based on BPE(Byte-Pair Encoding)
Numerical Representation for Search
Text Representation
Question ---> Retriever ---> Ducuments ⬆ | Load Documents | | DocumentsNumerical Representation
Question ---> Cosine Similarity, etc ---> [x,y,z...] ⬆ | Load Documents | | [x1,y1,z1...] [x2,y2,z2...] [x3,y3,z3...]Statistical and Machine Learned Representations
Bag of words Representation Search Statistical [0,0,2,0,3,5,0...] Sparse BM25
Documents
Machine Learned [0.002, -0.004...] Dense KNN, HNSW Embedding Representation SearchLoading, Splitting and Embedding
embeddingQuestion ------------> [x,y,z,...] ----> Index ---> Relevant Splits ⬆ | [x1,y1,z1...] [x2,y2,z2...] [x3,y3,z3...] ⬆ | | Embedding | Splits ⬆ ---> Charactors | |--> Sections | spliting ->| | |--> Semantic Meaning | |--> Delimiters Documents