
Object Detection
- Algorithms for object detection.
Object Detection
Object detection contains ‘Object Localization’ and ‘Landmark Detection’.
Object Localization
- Image classification (if there is a car in image)
- Image classification with localization (label the car in image and draw a boundary box of the car)
- Detection (detect and localize all cars in the image)
Classification with Localization
Network for classification: predict the class after softmax layer.
Network for classification and localization: change the output layer to contain 4 more numbers, ‘bx, by, bh, bw’. (add a bounding box)
Example of Defining the Target Label y (one object)
- pedestrian
- car
- motorcycle
- background
1 | [ Pc: is there any object? 1: one object, 0: no objects (when Pc is 0, other nums make no sense, don't care) |
Landmark Detection
If you’d like your neural network to output important points and their coordinates, which were called ‘landmarks’.
Example of Defining the Target Label y (landmark detection)
Detect 4 landmarks of the eyes on a person’s face:
- l1x, l1y (coordinate of left corner of left eye)
- l2x, l2y (coordinate of right corner of left eye)
- l3x, l3y (coordinate of left corner of right eye)
- l4x, l4y (coordinate of right corner of right eye)
1 | [ Pc: is there a face? 1: yes, 0: no |
Application for Landmark Detection
- AR augmented reality filters: like putting a crown on the face
- key building block for computer graphics
- People pose detections
Notice of Landmarks
Landmarks should be consistent through all data sets. (e.g.: landmark 1 should always be left eye and landmark 2 shou always be right eye)
Object Detection
To do object detection, you need a conv net to recognize objects and an algorithm called ‘Sliding Windows’.
One Object Detection in Each Cell
Sliding Windows detection
- Pick a small window size, start from left top corner, pass this rectangular window image to your ConvNet and make a prediction.
- Then slide the window a little bit over to right and feed that new region image into your ConvNet.
- Keep going until you slide the window through the entire input image.
- Pick a larger window size, repeat steps above.
Convolutional Sliding Windows
Biggest disadvantage of sliding window algorithm:
- Computational Cost. (Much duplicated computations)
- Position of bounding boxes isn’t too accurate.
Method to fix the computational cost is called ‘Convolutional Sliding Windows’.
Turn FC layer into convolutional layers
- change each FC layer into n filters (n refers to the number of units in this FC layer)
- the size of each filter matches the size of the prior output.
Convolution implementation of sliding windows
- Instead of feeding every region of the input into the ConvNet, you feed the entire original input image into ConvNet.
- With turning FC layers into conv layers, every number of the final output represents the result of the relevant position window.

Method to fix the position of bounding box is called ‘YOLO algorithm’.
YOLO algorithm
- Put a grid on the input image. (n * n grid)
- For each grid cell, after running the object classification and localization model, we get an output label y. (8-dimensions)
- YOLO algorithm: take the midpoint of the object and assign the object to the grid cell which contains that midpoint.
Define the Target y (YOLO algorithm)
1 | [ Pc |
Notice of YOLO
- YOLO is like classification and localization task before.
- Using convolutional implementation, rather than feed each single grid cell separately into the ConvNet.
- Works for real-time object detection.
Paper
You Only Look Once: Unified real-time object detection. (One of the harder to read)
Intersection Over Union
IoU could be used in both evaluating object localization and object detection algorithm.
Evaluate Object Localization
Intersection: size of the intersection between your bounding box and the ground truth box
Union: size of the union between your bounding box and the ground truth box
IoU = Intersection / Union, ‘Correct’ if IoU ≥ 0.5 (could also be ‘0.6’, ‘0.7’…)
Use in Object Detecting Algorithms
IoU is also used in ‘non-max suppression’ and ‘anchor boxes’ algorithms.
Non-max Suppression
During the classification and localization task, it’s common that the same object may be detected more than once. Since there are many gird cells say that they found an object.
That’s the reason we need non-max suppression.
Steps of Non-max Suppression (Detecting Single Object)
- discard all boxes with probability <= 0.6.
- pick the box that has the highest probability (kind of ‘Pc’), which means ‘the most confident one to have an object there‘. And this is one prediction.
- discard any other boxes that have a high ‘IoU’ (like IoU >= 0.5) with the selected one above.
- if there are any remaining boxes, repeat from step 2.
Notice of Non-max Suppression
- To detect n objects, you need to run non-max suppression n times.
Multi Objects Detection in Each Cell
There are more than one objects in the same area, which means multi mid-points in one cell.
Anchor Boxes
Pre-defined multi different anchor boxes, called anchor boxes and anchor box shapes.
Each object is assigned to the grid cell that contains object’s midpoint and anchor box with highest IoU.
Compared to ‘single object detection’ before, the object will not only be assigned to the gird cell by location of its midpoint, but also assigned to the appropriate anchor box which has the highest IoU with this object.
The object will be encoded in (grid cell, anchor box) in target label.
Example of Defining the Target Label y (two anchor boxes)
1 | [ Pc |
Notice of Anchor Boxes
- Can’t handle well in case that when you have two anchor boxes and three objects in one grid cell.
- Can’t handle well in case that when you have two objects of similar shape’s anchor box in one grid cell.
- While choosing shapes of anchor boxes, the automatically and stereotypically representative method is ‘K-means’.
YOLO with Components Above
Here is the relatively complete YOLO algorithm:
- put a grid on the input image and run convolution on the entire input image
- for each grid cell, we can get a target y with several anchor boxes
- use non-max suppression n times for n classes (car, motorcycle, pedestrian..), get the final output
Region proposal
Try to just pick few regions that make sense (contain objects) to run convNet classifier.
Segmentation Algorithm: turn image into many blobs.
R-CNN (Region-based Convolutional Neural Networks)
Propose regions. Classify proposed regions one at a time. Output label + bounding box.
Fast R-CNN
Propose regions. Use convolutional implementation of sliding windows to classify all proposed regions.
Faster R-CNN
Use convolutional network to propose regions.
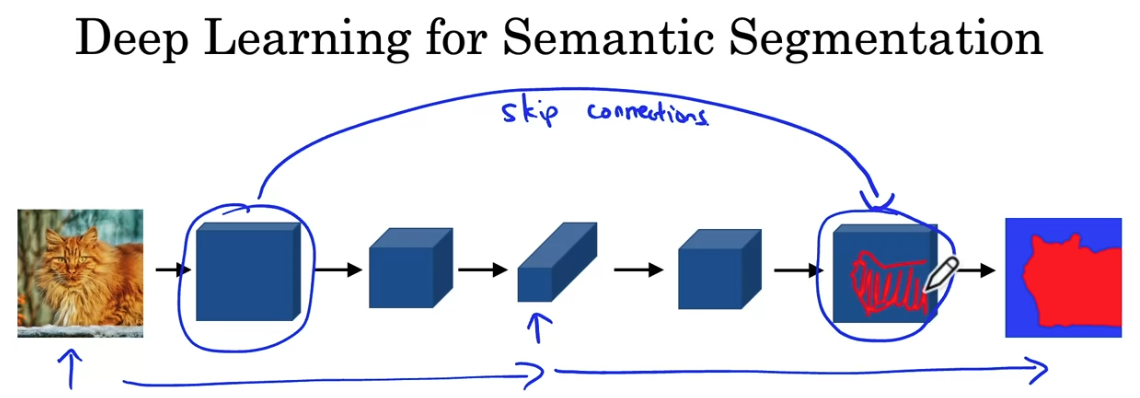
Semantic Segmentation
Label every single pixel to different classes.
Difference between Object Detection and Semantic Segmentation

One of the usage is for self-driving car tasks to figure out which pixels are safe to drive.
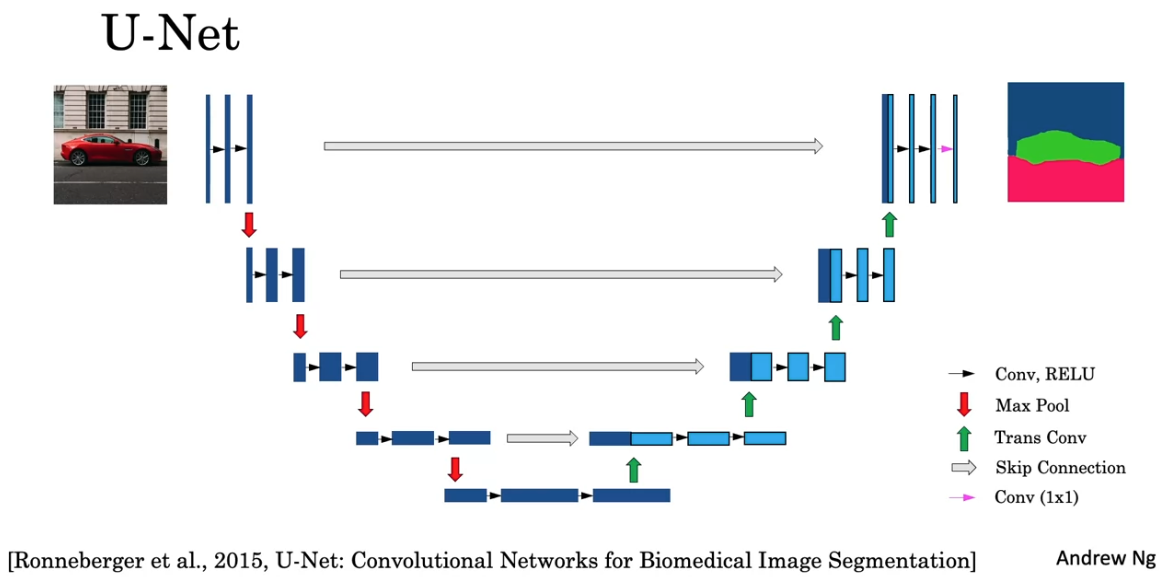
Segmentation with U-Net

Instead of giving a class label and coordinates specifying bounding box, segmentation algorithm (U-Net) outputs a whole matrix of labels.
Transpose Convolution
Normal Convolution: shrink the height, width and expand the channel
Transpose Convolution: expand the height, width and shrink the channel
U-Net
Reference: